Модели искусственного интеллекта, использующие данные искусственного интеллекта, могут столкнуться со смертельной спиралью
05.07.2023
Большие языковые модели порождают словесное загрязнение, которое угрожает подорвать сами данные, на которых такие модели обучаются.
К такому выводу пришла команда британских и канадских исследователей, изучающих влияние последовательных поколений сгенерированного в ChatGPT текста, который будет отобран для будущих моделей.
В статье, опубликованной на сервере препринтов arXiv и озаглавленной «Проклятие рекурсии: обучение на сгенерированных данных заставляет модели забывать», команда предсказала, что рекурсивный характер обучения ИИ в конечном итоге приведет к «коллапсу модели».
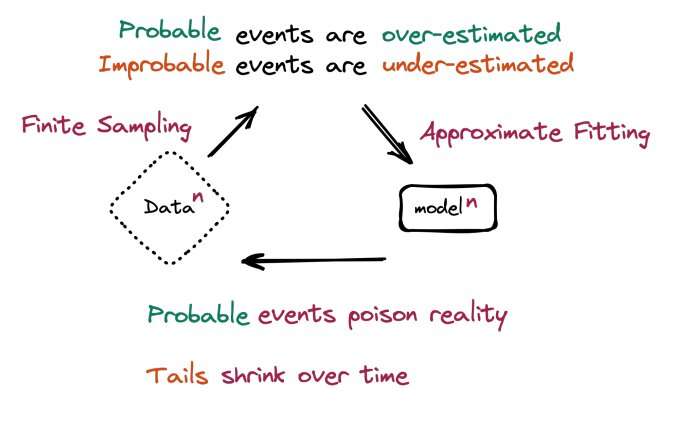
«Мы обнаруживаем, что обучение на основе данных, полученных с помощью других моделей, приводит к коллапсу модели — дегенеративному процессу, при котором со временем модели забывают об истинном базовом распределении данных», — сказали в команде.
Член команды Росс Андерсон из Кембриджского и Эдинбургского университетов сравнил этот эффект с ухудшением качества музыкальной продукции.
«Если вы обучаете музыкальную модель на Моцарте, — сказал он в личном блоге, — вы можете ожидать, что результат будет немного похож на Моцарта, но без блеска … и если [эта версия] обучит следующее поколение и так далее, как будет звучать пятое или шестое поколение?»
Авторы отмечают, что коллапс модели — это угроза, аналогичная катастрофическому забвению и отравлению данных.
При катастрофическом забвении модель «забывает» предыдущие данные, иногда внезапно, при изучении новой информации. Воздействие усугубляется с течением времени.
По словам команды, в своем новом исследовании модели не забывают ранее изученные данные, «а скорее начинают неверно интерпретировать то, что они считают реальным, укрепляя свои собственные убеждения».
Заражение данных — это злонамеренная вставка ложной информации. Конечно, эта практика предшествовала использованию больших языковых моделей. Но при использовании крупномасштабных веб-обходов вставка даже небольшого количества вредоносных данных, по словам команды, может привести к широкомасштабному заражению.
«Что изменилось с появлением больших языковых моделей, так это масштаб, в котором может произойти такое отравление, как только оно будет автоматизировано», — сказали в команде.
Исследователь Илья Шумайлов из Оксфордского университета предупредил, что «серьезная деградация происходит всего за несколько итераций, даже если часть исходных данных сохраняется».
«Ошибки, связанные с несовершенством оптимизации, ограниченными моделями и конечными данными, — продолжил он, — в конечном счете приводят к тому, что синтетические данные имеют низкое качество. Со временем ошибки усугубляются и в конечном счете заставляют модели, которые учатся на сгенерированных данных, еще больше искажать реальность».
Исследователи сказали, что природа рекурсивного обучения заключается в том, чтобы обходиться без событий с низкой вероятностью, называемых статистиками «хвостами распределения».
В своем блоге Андерсон предупредил: «Использование контента, сгенерированного моделью, в обучении приводит к необратимым дефектам. Хвосты исходного распространения контента исчезают. В течение нескольких поколений текст превращается в мусор».
«События с низкой вероятностью… жизненно важны для понимания сложных систем», — отмечается в отчете.
Первые крупные языковые модели были обучены на текстах, сгенерированных человеком. Но с быстрым внедрением ChatGPT промышленностью и обычными пользователями онлайн-сайты заполняются огромными объемами данных.
Исследователи настоятельно призвали предпринять шаги, чтобы отличить контент искусственного интеллекта от контента, созданного человеком, и приложить усилия для сохранения оригинального контента для будущих целей обучения.
«Большие языковые модели подобны огню, — сказал член команды Андерсон. — Полезный инструмент, но загрязняющий окружающую среду. Как мы с этим справимся?»